All published articles of this journal are available on ScienceDirect.

Computational Methods Applied to Rational Drug Design
Abstract
Due to the synergic relationship between medical chemistry, bioinformatics and molecular simulation, the development of new accurate computational tools for small molecules drug design has been rising over the last years. The main result is the increased number of publications where computational techniques such as molecular docking, de novo design as well as virtual screening have been used to estimate the binding mode, site and energy of novel small molecules. In this work I review some tools, which enable the study of biological systems at the atomistic level, providing relevant information and thereby, enhancing the process of rational drug design.
INTRODUCTION
Synergic relationship between experimental biochemistry sciences and computational theoretical methods has increased in recent years, providing significant benefits in different biological sciences areas, specially biochemistry and molecular biology. It has also brought advantages in medicinal chemistry for the rational design of drugs [1]. Regarding theoretical study of biochemical systems, one of its greatest profits is the molecular knowledge of the currently studied structures; these studies allow an exhaustive system analysis, and find meaningful answers to research questions that scientists face in their experimental laboratories.
Before exploring some of the computational methodologies currently used in drug design, it is important to consider that researchers have to draw from relevant information such as the three-dimensional structure of one or several substrates and molecular targets in order to start the theoretical study of certain biological systems. This information is essential, and in many cases, it determines the success or failure of the ongoing theoretical study. For instance, if a researcher wants to study the system formed by an endogenous or an exogenous inhibitor with its respective molecular target, the three-dimensional structure of the molecules involved in the interaction to be simulated has to be known.
The number of molecular targets with a well known structure is exponentially increasing due to the dramatic progress of spectroscopic techniques such as X-ray crystallography, Nuclear Magnetic Resonance (NMR) [2], and the development of the super-resolved fluorescence microscopy that shows a 3D image of a single molecule [3]. In addition, structures which have been produced from structural genomics have also become valuable tools for the study of systems whose molecular targets have not been solved yet [4, 5]. This growth has allowed a massive and constant use of computational tools in research centers worldwide. Furthermore, the developed methodologies for the production and optimization of small molecules (as most of the substrates studied in biochemistry sciences), are already registered in special databases and have provided vital information to research and find inherent characteristics which have never been described before [6, 7].
Nowadays, there are multiple computational methodologies used as bioinformatics tools for the study of biological
systems and drug discovery. The use of one or another tool is linked to the researcher interests, the calculation level intended, possible technical limitations, how and also which kind of information can be extracted from data processing and analysis. Some of the main methodologies for these studies are: Molecular Docking, de novo design, Virtual Screening (VS), Quantitative structure-activity relationships (QSAR), Molecular Dynamics simulation (MDs) and Molecular Modeling (MM) [8]. These methodologies are wieldy used for rational drug design and discovery processes, where the ligand receptor binding mode is imperative to understand the molecular interaction mechanism and the structural factors related with the bioactivity of each inhibitor in detail [9].
In this review, basic and significant elements of molecular docking, de novo design and virtual screening are shown. These are some of the greatest computational methodologies used for the analyses of biochemical sciences, which also improve the common techniques used to study proteins structures, the design of new molecules biologically relevant for pharmacological application, the structure activity relationship, among others.
Molecular Docking
Molecular Docking dates from the middle of the 19th century. Chemists Archibald Scott Couper, Friedrich August Kekulé and Aleksandr Mikhailovich introduced the valence in organic chemistry, and submitted the first structures with graphical representations of carbon atoms [10]. In 1861 Johann Josef Loschmidt produced the largest molecules collection at that time (368), including the first accurate benzene structure [11]. Due to the technological development in computational sciences, the concept of ‘force field’ was introduced from the vibrational spectroscopy, which consider the forces acting all over the atoms in a molecule. The scientific community did not adopt the concept of ‘force field’ until 1946, when the first premise about the combination of steric interactions and the Newtonian mechanics model of vibrational modes, bonds, and angles emerged.
Many other scientific advances were developed at that time, but it was in 1953 when Metropolis et al. published the study: "Equation of State Calculations by Fast Computing Machines" [12]. For the last century, the molecular modeling foundations were set, and due to the technological advances of our time, it now allows us to perform better theoretical studies and computational calculations and validates the need of using computational methods for science progress.
Molecular docking main goal is to predict as accurately as possible the best conformations (poses) of a ligand - by using a score function - in a conformational area, which is delimited by the molecular target binding site [13]. This is applied in different stages of the drug design process in order to predict the binding mode of the ligands already known [14]; it is also used to identify novel and potent ligands [15] and as a binding affinity predictive tool [16]. The first molecular docking algorithms considered translation and orientation only (degrees of freedom), and used the ligand and protein as rigid bodies. Improvements in computer science allowed the creation of new and accurate algorithms in order to use the ligand as flexible with a rigid (or nearly rigid) receptor [17].
This methodology is described as a multi-step process, where each step has one or several complexity levels. The process starts with the implementation of the molecular docking algorithms responsible for placing the ligands in the binding sites. This process is challenging, since it depends directly on the freedom levels granted to the ligands. The freedom levels sampling must be done accurately in order to identify the best conformation for the receptor-binding site. In addition, it has to be done fast enough to assess several compounds in a relatively short period of time [14].
These algorithms are complemented with scoring functions to sort different poses with the receptor regarding the union force. The scoring functions have some disadvantages because they do not take into account all the interfering forces between the ligand and the receptor; in addition, they also fail in accounting the ligand solvation, the entropic changes when bonding the receptor, the receptor flexibility and the receptor’s conformational changes induced by the same ligand interaction. Based on this, molecular docking is a technique quite fast and effective in terms of time and computational cost [18].
The main software and algorithms developers performing molecular docking are focused on improving aspects such as: receptor’s flexibility, solvation, coupling fragment, post-processing, molecular docking in homology models and comparisons between couplings. Main progress regarding this technique has taken place in the scoring functions area. The use of this methodology has been enhanced over the years; for instance, by doing a single search in PubMed using the word ‘docking’ as a search criterion, it shows the evolution of the publications where molecular docking has been used (Fig. 1).
Many authors have demonstrated that molecular docking software can produce "accurate" binding modes, providing acceptable solutions to the sampling problem; however, the main challenge between the programs and algorithms developers is the poses scoring problem [19]. In this sense, the molecular docking tools are powerful in the prediction of correct binding poses but have critical issues to estimate accurately the corresponding binding affinities.
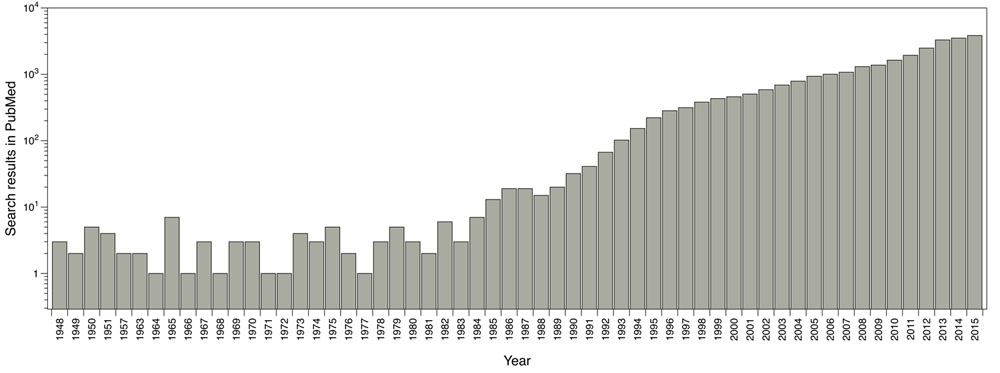
Reported publications number where molecular docking was used. Results from PubMed using the word ‘docking’ as search criteria.
An effort to improve affinity prediction, a rescoring process with other simple functions or solvated-based scoring functions is typically performed. The poses generated by docking program are taken, and methods such as MM/PBSA (Molecular Mechanics/ Poisson-Boltzmann Surface Area) and MM/GBSA (Molecular Mechanics/ Generalized-Born Surface Area) [19-21] include implicit solvent and can be used in order to correct scoring function values and improve docking accuracy. Other strategy is the use of molecular dynamics simulation (MDs) to get conformational sampling of the complex obtained using docking, performing then a subsequent calculation of the binding energy by averaging the score values for different poses extracted from the trajectory [22-24]. Under this approach, the receptor flexibility and the presence of explicit water molecules contribute to a more realistic description of the system, which could have an influence in binding energy calculations. However, the biggest challenge of molecular docking (and also the principal problem) is the accurate prediction of the binding energies, which has major implications for the prediction of novel effective drugs. This process is performed by using scoring functions that score the predicted poses [25].
Use of molecular docking programms between 2010 and 2011. Based on a PubMed search. (Taken and adapted from [18]).
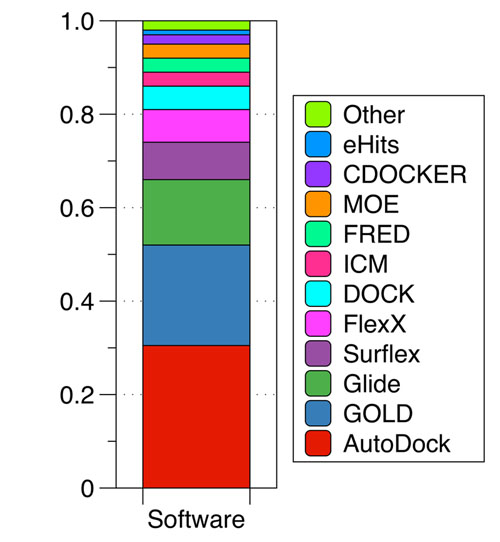
Several classes of scoring functions have been developed [25]. These consider the protein as a rigid body [26, 27], or as a soft body [28-30]. They also may consider flexible side chains [31] or certain flexible domains in the target [32-34]. Other empirical scoring functions have shown be useful in the virtual screening and filtering of databases of drug-like compounds at the early stage of drug development processes [34]. Frequently, scoring functions try to reproduce experimental binding affinities, but the ones with popular docking programs do not always yield the best predictions. New programs have arisen in recent years advertising the importance of Molecular Docking in the study of biochemistry sciences and drug design, the most widely used are AutoDock [33, 34] with 29.5% followed by GOLD [37] with 17.5% and Glide [27, 36] with 13.2% (Fig. 2).
Generally speaking, theoretical molecular docking aspects are within the thermodynamics principles, where the main goal is to accurately predict the complex Receptor-Ligand structure [R-L] in equilibrium conditions (Equation 1). As an example in Fig. (3) it was set the Receptor [R] (acetylcholinesterase), the ligand [L] (donepezil), and the complex [R-L] for this particular system.
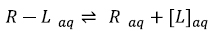 |
(1) |
Fig. (3) illustrates the ligand Donepezil [39] union (drug used in pharmacological therapy against Alzheimer's disease [40]) to the receptor Acetylcholinesterase described through the Gibbs free energy of binding (∆GBind); this energy is related to the binding affinity by the ratio of Equation 2:
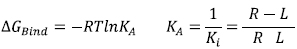 |
(2) |
KA is the affinity constant and Ki is the inhibition constant. The prediction for the accurate structure of the [R-L] complex does not require the experimental information of the constants; however, the prediction of the ligand biological activity does. The terms influencing the scoring function can be classified as follows: Consideration of the [R-L] complex, where aspects such as the ligand and receptor deformation, hydrogen bonds, and electrostatic and steric factors are important. When the equilibrium is considered (Equation 1), the most important factors are: desolvation, rotational and translational entropy.
Molecular docking has been widely used in rational drug design in the past decades with extensive applications in several issues such as:
- The theoretical study of antitubulin agents with anti-cancer activity [41].
- The study of the estrogen receptor binding domains [42].
- Shityakov et al. have studied the blood-barrier permeation by In silico predictive models [43, 44], the dimer complexes of dopamine and levodopa derivatives to assess drug delivery to the central nervous system [45], and the interaction of nanoparticles with multidrug resistance protein [46].
- The prediction of anti-cancer drugs for the treatment of hypopharyngeal cancer [47].
- Sabogal et al. established a protocol to identify an interaction pattern between the sea anemone neurotoxins and the potassium channel Kv1.3 [48].
- Yi et al. studied the metabolic behavior of anisole by using Molecular Docking [49].
Ligand donepezil binding to acetylcholinesterase (based on the crystalline structure PDB: 1EVE [39]).
Academically, the amount of research groups who use this technique to study biological systems have increased. In biology, computational techniques have taken great strength, especially in the structural biochemistry field. To prove it, a large number of articles such as the Structural Biochemistry Group at the University of Edinburgh for instance (website: http://www.bch.ed.ac.uk/index.php) have been published. In addition, at multidisciplinary centers of study such as the Department of Molecular and structural Biochemistry of the North Carolina State University - USA (website: http://biochem.ncsu.edu), study programs like biochemistry, molecular biology and biophysics in undergraduate, masters and doctorate levels have been created. This allows students to familiarize with the technique, including it in their academic activities. For these reasons, molecular docking is not only used in the pharmaceutical industry for drug discovery, but also for anyone interested in the study of biological systems and receptor-ligand interactions.
de novo Design
Another computer-based drug design method known as ‘de novo design’ have been implemented to find new potent and selective ligands. de novo design serves as a tool for the discovery of new ligands for biological targets as well as optimization of new ligands [50]. These tools produce (from scratch) novel molecular structures with desired pharmacological properties [51]; subsequently the new structures are docked to find the binding affinities and interacting modes. This new tools and algorithms identify potent ligand-protein interaction characteristics in the binding site, and construct novel molecular structures by assembling atoms and molecular fragments either combined or sequentially. de novo design is a powerful tool, and some authors have reported most potent ligands designed by this tool that their precursors [52], revealing the importance of this tool in the drug design process. Some of these new tools are shown in Table. 1.
de novo design tools (taken and adapted from [53]).
| Tool | Concept | Reference |
|---|---|---|
| Builder | Combinatory search by recombination of docked molecules | [54] |
| Caveat | Database search for fragment fitting | [55] |
| Concerts | Fragment-based, stochastic search | [56] |
| Dynamic ligand design | Atom-based, structure sampling by simulated annealing | [57] |
| GenStar | Atom-Based, molecules growth based on an enzyme contact model | [58] |
| GroupBuild | Fragment-based, combinatorial search | [59] |
| Grow | Peptide design, sequential growth | [60] |
| Growmol | Fragment-based, sequential growth, stochastic search | [61] |
| Hook | Linker search for fragments placed by MCSS | [62] |
| Legend | Atom-based, stochastic search | [63] |
| LUDI | Fragment-based, combinatorial search | [64] |
| MCDNLG | Atom-based, stochastic search | [65] |
| MCSS | Fragment-based, stochastic sampling | [66] |
| MolMaker | Graph-theoretical 3D design | [67] |
| NewLead | Fragment-based, builds on 3D pharmacophore-models | [68] |
| Pro-Ligand | Fragment-based search | [69] |
| Pro-Select | Fragment-based, scaffold-linker approach | [70] |
| Skelgen | Small-fragment based, Monte-Carlo search | [71] |
| SME | Peptide design, whole-molecule optimization | [72] |
| SMoG | Fragment-based, sequential growth, stochastic search | [73] |
| Splice | Recombination of ligands retrieved by a 3D database search | [74] |
| Sprout | Fragment-based, sequential growth, combinatorial search | [75] |
| Topas | Fragment-based, evolutionary search | [76] |
Automated de novo design is a very useful tool for hit and lead-ligand identification; design molecules, provide ideas for medical chemist and pharmaceutical industries, and to develop novel leads with desired chemical characteristics.
Virtual Screening
A computational technique widely used in drug design is Virtual Screening (VS). Its main objective is to search for specific information in compounds or molecules libraries with similar structural properties that can acceptably interact with a therapeutic target and is an important tool to access novel drug-like compounds [77]. Prior to the VS, massive molecular docking was used but it had a big computational cost and spent a lot of computational time; due to this, a technique - which enables the efficiency improvement to search for compounds in large molecular libraries - was needed. The use of VS (as well as molecular docking) has increased in recent years, rising from an average of 10 publications reported in the 70s - 80s, to an average of more than 1000 publications reported in previous years (Fig. 4).
Reported publications number where virtual screening was used. Results from PubMed using the words ‘virtual screening’ as search criteria.
Virtual screening can be performed through two approaches, Ligand-Based Virtual Screening (LBVS) and Structure-Based Virtual Screening (SBVS). LBVS is used when there is not knowledge about the three-dimensional structure of the therapeutic target (receptor), and yet you have a group of molecules with some biological activity against that target; in that sense, structure relationships can be determined. The molecules group with reported activity can also establish the molecular characteristics. These characteristics allow the interaction between the molecules and the molecular target. Based on those (such as acceptor and donors hydrogen bonds, metals, hydrophobic moieties, aromatic rings among others), researchers can screen databases to find other molecules to fit in the profile of the initial group – with the same molecular descriptors – which can possibly present biological activity against the studied therapeutic target [78]. In the LBSV the lead-ligands generated are ranked based on their similarity score obtained by different methods or algorithms [77].
On the other hand, Structure-Based Virtual Screening (SBVS) establishes its action mechanism in the studied molecular target structure and begins with the identification of the potential ligand-binding site on the target. Then, one of its greatest challenges is to determine the target 3D structure by NMR, X-ray crystallography or molecular modeling. Later, an automated and rapid docking of a large number of chemical compounds against the 3D structure of the molecular target is done. This technique has helped with the identification of potential therapeutic molecules for specific pathologies [77].
To use this technique in an effective way, a protocol with several stages should be established:
-
Ligands Database Preparation
It is necessary to prepare all the molecules to be studied with the SBVS. Tautomers, isomers, protonation states, ionization states, enantiomers, etc. must be considered. This database must be prepared in accordance with the software to use. -
Receptor Preparation
Next, the molecular target (Receptor) must be provided. It may uses the same ligands database preparation software. -
Molecular Docking
It is necessary to determine the common pharmacophore in the ligand database; after this - and through the appropriate program - massive molecular docking is carried out. -
Post-Processing
The post-processing is performed in accordance with the user requirements through the analysis of the score function, geometric analysis, shape complementarity, solvation corrections, entropic changes, pose clustering, etc. -
Compounds Selection
The final step is the compounds selection for biological tests, or to be further analyzed by other computational techniques [79].
Nowadays, there are several comprehensive programs used to perform VS such as: AutoDock Vina [35], Glide [28, 38, 80], DOCK [81], FlexX [82], GOLD [37], ICM [83], among others. Additionally - and due to the high computational cost for the SBVS implementation - several research groups around the world have developed free software and algorithms to be accessed through virtual platforms. These developers also have the advantage of having extensive updated databases, which allows the virtual screening of millions of molecules. For instance, among the major online servers to perform VS there is the ZINCPharmer, sponsored by the University of Pittsburgh (website: http://zincpharmer.csb.pitt.edu) [84]. This software allows researchers to perform online SBVS for free, mainly based on the established ligand pharmacophore used as input. The screening is basically performed in the ZINC database [7], a non-commercial database with more than 22 million compounds.
In recent years, researchers who use this technique in their computational research have increased, and the establishment of data sets for potential therapeutic agents from VS can be observed, for example: SENP2 inhibitors [85], kinases proteins agonists [86], inhibitors with vasodilator activity [87], inhibitors of HIV-1 reverse transcriptase [88], among others.
The development of these dataset has allowed the access and use of information more efficiently, by evaluating compounds against new molecular targets and finding many potential drug candidates (better than those before the implementation of this technique).
Some active compounds identified by computational methods.
| Compound structure | Use | Computational method | References |
|---|---|---|---|
 |
Antimycobacterial agents | Virtual Screening | [89] |
 |
SENP2 inhibitors | Virtual screening, Molecular Docking | [85] |
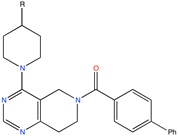 |
TASK-3 channel antagonist | Pharmacophore based virtual screening | [90] |
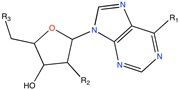 |
GAPGH inhibitor | Combinatorial docking | [91] |
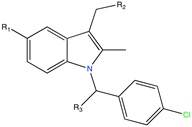 |
Aldose reductase inhibitor | LBVS | [92] |
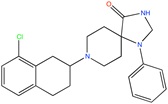 |
Ca2+ antagonist | Pharmacophore searching | [93] |
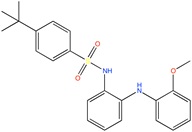 |
Kv1.5 channel blocker | Fragment based, de novo design | [76] |
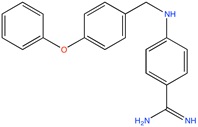 |
Thrombin inhibitor | Combinatorial docking, de novo design | [94] |
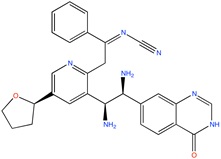 |
Antiretroviral agent | Virtual Screening | [95] |
On the other hand, VS is used as a mechanism for the evaluation of new potential drugs against certain molecular targets in rational drug design. In biochemical terms, this enables the computational evaluation of large molecules quantities in a short time with a relatively low computational cost. It means that after a screening, score, post-processing and visual inspection, it can continue to the laboratory to perform in vitro testing with the best candidates obtained via VS allowing the properties evaluation such as the biological activity, the enzyme kinetics, among others. This contributes with the biological system study in the drug discovery process.
Several bioactive molecules identified, optimized or designed by using molecular docking, de novo design or VS methods (Table. 2) let us understand the importance of the application and use of them as computational tools for drug discovery to explore the chemical space of a binding site and present novel, potent and selective pharmacological alternatives in medical chemistry and drug discovery.
CONCLUSION
Although in appearance, a direct relationship between the computational methodologies - molecular docking and virtual screening - with research in biological and medical sciences does not exist, in recent years most of the authors whom develop biological systems research in areas such as biochemistry, medicinal chemistry, pharmacology, organic chemistry, theoretical chemistry, etc., use computational methods to support, improve and reinforce their research. The structural studies of these systems at theoretical level assist with the construction of a wide and accurate perspective of the issue, and enable the knowledge consolidation.
In addition, there is still a long way to develop methodologies with “thinner” approaches (accurate and precise). Although methodologies such as the molecular docking and virtual screening are effective (in terms of time and computational cost), they have also a poor predictive capability. There are other methods involving a higher calculation level for researchers who study dynamic biological systems (Molecular Dynamics), or bonds and interactions in an electronic level (Quantum Mechanics). These like the other methods are more time-consuming in terms of computational cost, but may provide better results; it all depends on the researcher interests and funding. However, to improve computational techniques such as Molecular Docking and Virtual Screening, a change in the structural paradigm is needed, and this will be achieved when the understanding of the interactions between a drug and a receptor improves.
CONFLICT OF INTEREST
The author confirms that this article content has no conflict of interest.
ACKNOWLEDGEMENTS
I thank to Universidad de Talca for doctoral scholarship.

